


The map of biology and its ties to technology
Examples of how technology and biology are merging in today's world.


Youtube is great for binging vlogs or discovering how silly cats can be, but there’s also an amazing video on there called ‘The map of biology’. It’s made by Domain of Science and summarizes the different parts (subfields) of biology in a visual way. Let’s explore some of these different parts and how technology increasingly ties into each of them to get a better understanding of how vast the Tech x Bio space is and can become.
Zooming in on the molecules of life
Molecular biology studies the molecules that make up life. We can distinguish four major classes of macromolecules that are the vital building blocks of life: carbohydrates, proteins, lipids and nucleic acids. All of those are important, but I want to highlight two related examples for proteins and nucleic acids, to show how technology has tied into molecular biology today.
The first example, and arguably the most impactful to this day, is AlphaFold. It is an artificial intelligence (AI) system developed by Google DeepMind that is able to accurately predict protein structures. This might sound boring at first, but proteins are immensely important in nearly every biological process in your body. Proteins occupy a tremendous array of functions, and every function dictates this 3D shape that a proteins establishes: form follows function. This is exactly the reason why scientists are interested in this 3D shape, and it’s also the reason why DeepMind has been tackling the ‘protein folding problem’ since 2016.
Without going over the nitty gritty details, the AlphaFold system works as follows. It starts from a protein sequence (the string of its constituent chemicals we call amino acids) we want to predict the structure for, and searches public databases for similar sequences and whether those have known experimental structures. This collection of similar sequences (processed into what known as a multiple sequence alignment) and known structures are the two inputs of the system. Then it uses a complex artificial neural network called Evoformer that refines these inputs by exchanging information between them. Finally, the refined inputs are put through the third part of the AlphaFold system, a module that predicts the final structure. This means that for each of the amino acids in the protein sequence, a 3D coordinate is predicted. This concludes the system: protein sequence in, protein structure out. And AlphaFold does this blazingly fast. Experimentally determining the structure of a protein might take you several years, whereas AlphaFold predicts structures in minutes. Obviously, not all predictions are of a sufficiently high quality, but this new era in structural biology with AlphaFold will help scientists better understand diseases, find new medicines, and likely increase our fundamental understanding of our own biology. AlphaFold is a big deal.
The second example is a lot less known, but is equally impressive. Predicting protein structures is hard, but apparently predicting the structure of RNA molecules is even harder! This is both because a lot less RNA structures have been experimentally determined compared to proteins, and related RNA sequences share a lot less coevolutionary information that could be used to predict the structure. For this reason, when predicting an RNA structure, it is crucial to know if the prediction is actually worth anything, which has been a challenge on its own. Last year, researchers at Stanford have solved this problem. They have designed a deep neural network that can accurately estimate the error of a predicted structure, i.e. the network accurately estimates the deviation from the true unknown structure. The most impressive detail: the group has managed to train their complex model on a mere 18 RNA structures! One particularly interesting development this research could further enable is the discovery of RNA-targeted drugs.
Biotech 4.0
Prof. Marjan De Mey is a professor at our faculty of Bioscience Engineering, Ghent University. She’s known for her expertise in synthetic biology and metabolic engineering. In a recent blogpost (in Dutch), she elaborated on the four waves of microbial biotechnology, which paints a clear example of how technology increasingly ties into biology. Let’s break that down.
The first wave of microbial biotechnology essentially started out as a search to better understand industrial fermentation, particularly to produce beer. A notable early example here was the Carlsberg institute that was founded in 1875. Then, the first and second World Wars further fueled innovations in the fermentation industry, leading to the large-scale production of a wide range of products other than beer, such as penicillin, steroids, cortisone etc.
The second wave started in 1973, when Cohen and Boyer discovered recombinant DNA technology. This scientific breakthrough enabled genetic engineering, essentially allowing scientists to adapt microbial cells to produce new molecules that they wouldn’t naturally produce. This both led to skepticism around the world, as well as an increased interest of what we could do with genetically modified microbial cells. One important example here is the production of insulin, which is used to treat type I diabetes. Prior to genetic engineering, it had been (cumbersomely) extracted from animals, which was far from an ideal process. In 1978, Genentech announced its production of synthetic human insulin, which greatly improved the production process compared to what it was before.
Since a few years, we’ve arrived at Biotech 3.0. The continued development of new techniques and technologies into what we now know as synthetic biology, fueled a third wave of innovation in biotech. Today, we can put together engineered microbial ‘factories‘ that produce a range of complex molecules such as plant metabolites and human milk sugars; we can create specialized enzym complexes that break down agricultural waste (see here, in Dutch) and much more.
Where is this going in the future? We’ll likely see a fourth wave - Biotech 4.0. In this fourth wave, besides synthetic biology, we will increasingly see applications of machine learning and nanotechnology in the field that can enable a future of extreme customizability with tailored microbial factories that produce an array of molecules and fabrics. For example, imagine 3D printing new clothes using your old clothes that you haven’t worn for years. Fast fashion could become a lot more circular and sustainable that way. Another futuristic example is a personalized microbial waste processor, which breaks down household waste and converts it into energy for use in the house. Prof. De Mey concludes that “microbial biotech 4.0 will fully make use of nature’s diversity and utilize it in a dynamic way to increase the quality of life of humans”. I think that’s a great vision to put into reality.
Looking through the lens
Cancer is one of the most important disease of our time. Rightfully so, here in Belgium, it’s a disease that gets a lot of attraction (and thus funding for research) each year due to various organizations (such as Kom op tegen kanker) raising awareness and raising money.
Essentially, cancer cells are cells that keep growing and dividing, ignoring signals to stop growth (among other abnormal behaviors). So when researchers look for potential drugs against cancer, one key outcome they look at is the halting of cell division. Cells that stop dividing can be detected is various ways, by looking at so-called markers. For example, such markers could be proteins that regulate cell division or the cell’s cytoskeleton. To detect such markers, researchers often look at cells under the microscope, where markers of interest are colored by fluorescent probes. By using fluorescence microscopy, researchers can then quantify the presence or absence of markers within cells, which is exactly what we’re interested in! We might come across images like the ones below.
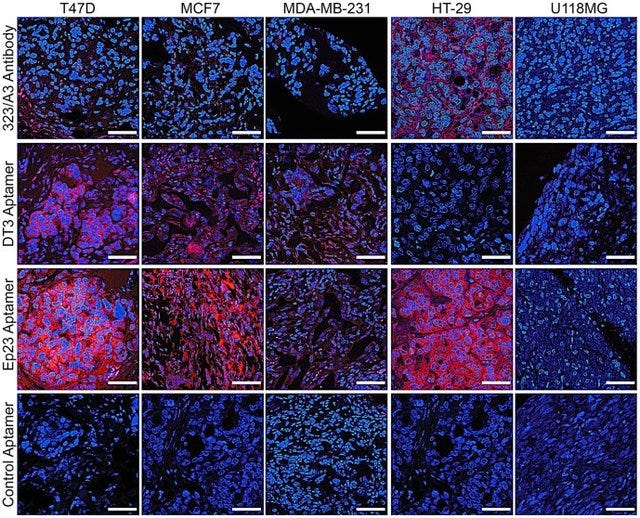
Here as well, AI systems can help us look through the lens much faster, by automating the analysis of microscopy images. Manual curation of images can be very time consuming and requires expert knowledge, making it hard to scale. This is where AI can provide value. Paradoxically, to get started and train an AI model, researchers need to manually label a large number of images first! An interesting trend here is the application of what’s called transfer learning, which involves a system that is trained on one set of data to then have it make predictions for things it was not originally trained for. As an example, researchers at UCSF and Google have developed a deep learning model that can reliably predict a set of fluorescent labels and showed that other, new labels can also be predicted using minimal additional data.
Another welcomed trend is the democratization of such AI systems in the biology field, bringing the capabilities of AI to the masses (a.k.a. the nerdy biologists that want to play around). A set of English and Finish researchers, for example, leverage free cloud compute provided by Google to open source deep learning tools for microscopy. An in-depth view at this however, is for another blogpost ;).
This is probably only the beginning
As Domain of Science concludes in the video,
If there is one word that describes biology, it is complexity. There is a huge amount we still don’t understand about how life works.
And that is in fact a driver to look for inspiration in other fields and adapt tools and techniques from those fields. As I’ve mentioned before (from Demis Hassabis), AI could very well be the perfect descriptor for biology, exactly due to this complexity. And looking at the examples above, it is obvious that it will continue to guide us in a quest to continuously increase our understanding of biology and push the limits of what is possible.