

Technology and biology are blending together
Technology and biology are blending together
But what does that mean exactly?


[technology x biology], that is what this blog is about, but what does that mean? In this blogpost, we will take a deep dive into what this new blended field entails, connect several dots to explain how we got here and explore different points of view comprehensively.
Welcome to the field of TechBio
Whereas the fields of technology and biology have been blending together for several years now, the term ‘TechBio’ had its first appearance on the web when it was coined by Artis Ventures in 2019. The term has been defined as ‘the technology revolution finally arriving in the field of biology’, with an emphasis on:
An engineering-first approach to biology
An artificial intelligence (AI) driven discovery and exploration of biological data
A focus on efficient drug discovery/development with cures instead of treatments as a goal, in a personalized way.
Some also write the term as ‘Tech x Bio’, or in full ‘technology x biology’. I personally like the ‘x‘ in between as it clearly signals a binding or merging of the fields.
The term as originally coined by Artis Ventures is often seen in the specific context of companies, like Vijay Pande writes about, calling it ‘industrialized bio‘ and ‘the industrial bio complex’. But we can broaden our view beyond looking at companies. I’d say Tech x Bio can be seen as a new era in biology, in which reading biology, writing biology and engineering/programming biology are the new cornerstones for both research and development and they are all fueled by AI.
Given the definition above, we could also argue that Tech x Bio is a new iteration of biotechnology. When I think of biotechnology, I would broadly define it as understanding and adjusting biology to better suit human needs. A prime example I will always remember of my education is golden rice, an engineered variety of rice containing a precursor of Vitamin A that is able to combat Vitamin A deficiencies (which leads to blindness, immune disorders and more) in countries that mostly consume rice. In a way, golden rice is a very primitive example of this blending of technology x biology, applying an engineering-first approach and coming to a cure instead of a treatment. Hence my interpretation of it as a new iteration of biotechnology.
Another, more general concept related to Tech x Bio that I haven’t seen linked to explicitly is the famous ‘Danger Formula‘ of Yuval Noah Harari:

Harari explains that if we possess enough (1) biological knowledge and combine that with (2) enormous computing power and (3) data to feed to AI systems, we will reach a point where AI systems are able to predict almost any aspect of human biology, and thus we will be able to engineer (‘hack‘) any aspect of human biology. Although Harari’s formula seems scary, and Harari explicitly wants to express his concerns with it, the Danger Formula is actually a great condensed description of what Tech x Bio can encompass! Let’s look at the three pillars of the formula in more detail, in reverse order.
The sequencing revolution leads to an abundance of data
Underlying the last pillar ‘Data’ is an important technology called sequencing. In the world of biology, sequencing is the determination of an organism’s (or any other biological entity’s) genomic DNA code, consisting of a long string of A, C, T and G, which represent the four chemical molecules that make up our DNA. The first iteration of sequencing has been around since 1977 (developed by Sanger and colleagues) and was very expensive and slow. But in the last two decades, we went from sequencing a human genome for $100,000,000 in 2001 to less than $1,000 today.
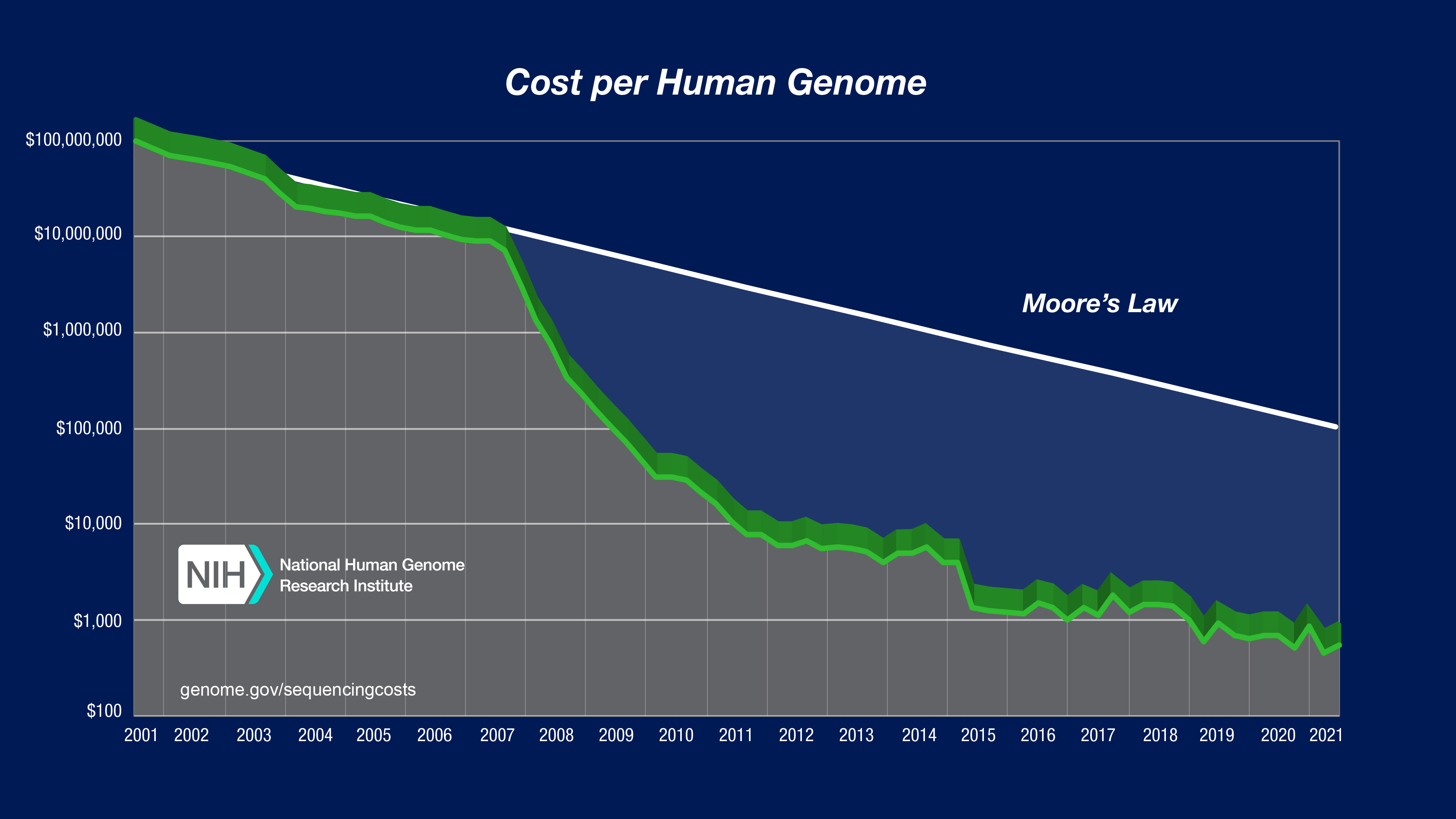
This massive drop in price has made sequencing genomes an increasingly standard practice in laboratories around the world. The important consequence of that is the increasingly large amount of biological data available in public databases. And this neatly ties into the second pillar of the Danger Formula: the cheaper it is to generate biological data, the more it invites scientists to work with that data using computational tools and methods.
AI and computing revolutions lead to digital biology
Moore’s law, as seen in the picture above, originally described the observation that the number of transistors in an integrated circuit doubles every two years, and thus the processing power doubles with it. As computers have gotten increasingly powerful, data storage capacity has also increased with it. Together with broad access to the internet, all of these advancements have fueled a new wave of AI that is only getting bigger. So you could say that the computing revolution led to the 21st century AI revolution, which now is increasingly being applied in biology, leading to this new era of digital biology.
Digital biology is an interesting new term that I only recently encountered in a post on Science about AlphaFold (an AI system capable of predicting protein structures). The term perfectly describes both the emerging trend of scientists to look at biology in a digital way (because more data are available!) as well as the software part of Tech x Bio. This software part is not necessarily AI-driven, but if we see the amount of publicly available biological data further increasing, it is only natural to assume that AI will be increasingly applied to those data. As Demis Hassabis of DeepMind sees it, “AI might just be the perfect descriptor for biology”.
Thus, when Harari describes the second pillar of his formula as computing power, he actually means the computing power itself (hardware) and the software systems running on the hardware. These software systems are digital biology systems.
What these digital biology systems can do (that’s their promise at least) is accelerate biology by making lab work less labor- and cost intensive, which leads us to the first pillar of Harari’s Danger Formula.
Data and AI lead to more fundamental knowledge
Harari’s first pillar, Biological Knowledge, is probably the most fundamental one at first sight. However, it is important to realize that both other pillars can actually contribute to this first pillar as well. Biology was an empirical science, but due to the sequencing revolution we can read biology and understand it way better than before. As a natural consequence, now we can also write biology better and better.
A beautiful example is the development of the SARS-CoV-2 mRNA vaccine by Moderna. Chinese researchers had managed to sequence the SARS-CoV-2 a mere 10 days after the first reported cases in Wuhan. As a result, companies like Moderna were able to quickly get to work developing a vaccine. In just a little over a month, Moderna delivered its first doses of their vaccine to the NIH for testing. This means that in just a little over a month, Moderna went from ‘reading’ the SARS-CoV-2 DNA (and acquiring new biological knowledge) to ‘writing’ a vaccine. That fast pace of reading and writing biology is remarkable and hasn’t been seen pre-Corona. Likely however, such feats will be a further catalyst for future developments of drugs and vaccines.
In more recent work, researchers have been able to piece together a model of the nuclear pore complex, one of the largest molecular machines in human cells, with the help of AlphaFold. Again, this example nicely illustrates the power of data, and here an AI system as well, to generate new biological insights.
So what does [technology x biology] mean? A lot! We’ve looked at different points of view on the topic and connected the three pillars of Harari’s Danger Formula to the field of Tech x Bio. The next posts will continue exploring this new field and its various aspects, stay tuned!